My Tryst with Out of Memory (OOM) Error: Taming High-Volume ML Pipelines on Limited Hardware
How I Fixed Memory Bloat in a Prefect-Orchestrated Workflow Without RAM Upgrades
The Breaking Point
There I was—wrapping up Module 3 of DataTalksClub’s #mlopszoomcamp. My mission: orchestrate an ML pipeline for a high-volume dataset using Prefect, with MLflow tracking experiments. Everything ran smoothly until...

The dreaded Out of Memory (OOM) error struck during data transformation. With millions of records and high-cardinality features, my 16GB RAM AWS EC2 instance was gasping. Here’s the twist: I refused to add RAM. Why? To simulate real-world constraints of local machines/laptops where hardware upgrades aren't always possible or where budget provisions for scaling up compute in cloud virtual machines are not approved readily.
The Hardware Gambit
Initial EC2 setup: 16GB RAM + 30GB storage (barely more than a typical laptop)
Deliberate constraint: Avoided RAM upgrade to mirror local-dev limitations
Storage expansion: Added 20GB storage (total 50GB) to create breathing room
Swap strategy: Allocated 30GB of this for swap file virtual memory
2 Battle-Tested Fixes + The Swap Revelation
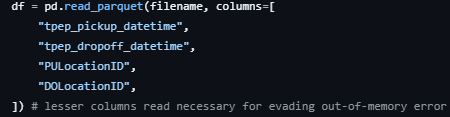
Surgical Data Loading
Problem: Loading all columns wasted memory
Fix: Select only essential features upfront:
df = pd.read_parquet('data.parquet', columns=['required_feature(s)', 'target'])

sudo swapon /swapfile
Why This Matters for Local Development
Real-world simulation:
30GB storage mimics limited laptop SSD space
Fixed RAM mirrors consumer hardware constraints
- The swap insight:

Used 30% storage for swap to avoid 100% RAM cost
Achieved 32GB effective memory (16+16GB swap used) for heavy transformations and training
The Victory Lap
Prefect workflows executed end-to-end with OOM conquered
MLflow logged artifacts reliably despite memory pressure
Models trained on 3M+ records using storage as memory
| Resource | Initial | Optimized | Purpose |
|---|---|---|---|
| RAM | 16GB | 16GB | Fixed constraint |
| Storage | 30GB | 50GB | Expanded for swap |
| Swap File | None | 30GB → 16GB | Right-sized virtual memory |
Comments
Post a Comment